Result Summary
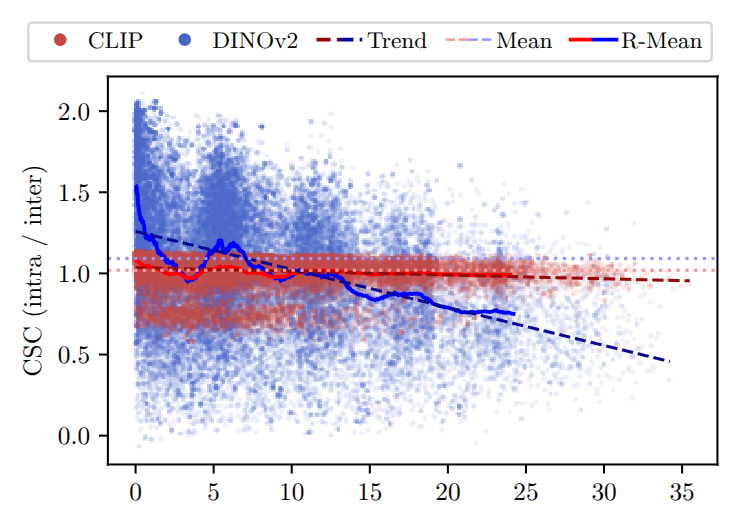
Embedding Instability Across Viewpoint Changes: Semantic consistency decreases as the difference in observation angle increases. When the same object is observed from different viewpoints, the resulting embeddings become less similar, indicating that semantic representations are not invariant to viewing direction. This effect is relatively small for CLIP, which maintains a near-zero slope, but becomes much more pronounced for DINOv2, where consistency drops significantly as the angle difference grows. The plot shows how semantic consistency (CSC) changes as the observation angle difference increases. The x-axis represents the angular difference between two observations of the same object, and the y-axis represents the consistency score. CLIP maintains a relatively stable behavior with a near-zero slope (−0.00229), indicating that its embeddings remain consistent across viewpoints. In contrast, DINOv2 exhibits a much steeper negative slope (−0.02345), meaning that its embeddings change significantly as the viewing angle varies. Although both models observe the same physical crops, the resulting embeddings diverge as viewpoint differences increase. This demonstrates that semantic representations are not invariant to viewpoint changes, and such instability can directly degrade the reliability of semantic maps.
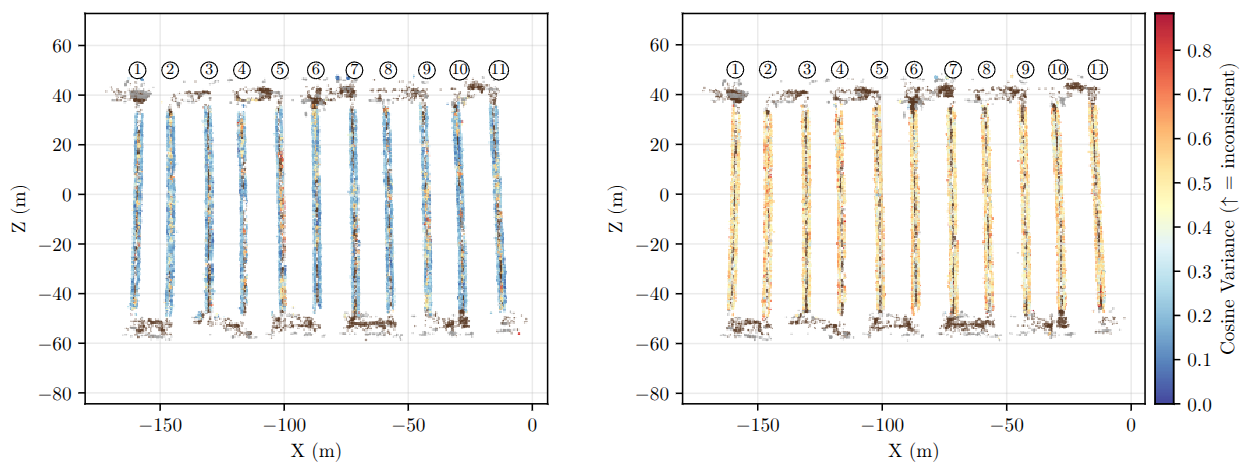
Spatial Instability of Semantic Embeddings: Semantic consistency is not uniform even within structurally identical regions. When examining embedding variance across the map, some areas produce stable and consistent representations, while others show large variability despite corresponding to the same crop category. The plot is a top-down visualization of embedding variance across crop regions. Each voxel in the map is colored based on the variance of embeddings assigned to it, where red indicates high variance (low consistency) and blue indicates low variance (high consistency). While all crops belong to the same semantic category, the figure shows that some regions produce highly consistent embeddings, whereas others exhibit large variability. Notably, this inconsistency appears even within the same crop row, which should ideally share a uniform semantic representation. Comparing models, CLIP produces more consistent embeddings overall, while DINOv2 shows higher variance across many regions. This result highlights that semantic inconsistency is not only caused by viewpoint changes but also emerges spatially within repetitive structures, leading to fragmented semantic representations in the final map.
